当春节遇上中国大模型在全球的火爆
2025 年 1 月 20 日,正当国内打工人忙着准备农历新年的热闹时,DeepSeek-R1 的发布在 AI 领域投下了一枚深水炸弹。这个开源模型在数学推理(AIME 79.8%)、代码修复(SWE-bench 49.2%)等任务上,首次以开源身份全面对标 OpenAI 的闭源旗舰 o1-1217,甚至在部分场景中实现了反超,而其成本却不到对方的十分之一。随后几天,这枚炸弹引发了硅谷强烈反响,科技公司投入上千亿巨资的合理性被纷纷质疑,甚至触发了科技股有史以来最大跌幅。
硅谷的焦虑与中国的年夜饭
虽远在老家深山,但却离不开 X (原推特)的第一手信息。无论这枚炸弹实际威力如何,海外舆论已将其解读为中国 AI 能力的一次巨大宣示。r1 的流量在 X 上连续热议了 3-5 天,reddit、hacknews 等平台上相关讨论层出不穷,DeepSeek app 甚至直接登顶中美 appstore 双榜单。这种局面无不让人联想到春节拜年饭桌上的热烈氛围。
大众讨论的焦点,除了对中国 AI 技术的肯定,更有对美国大型科技公司巨额投入的疑问。最引人注目的,是 deepseek 训练出与 o1 媲美的模型,但成本不及对方十分之一,这无疑为开源社区注入了一针强心剂。正如 OpenAI 的山姆·奥特曼在推特上写道:“deepseek r1 令人印象深刻,尤其是考虑到它的价格。我们将会提供更好的模型,有新的竞争对手令人振奋。” 这句话在赞许中蕴含着对自身模式的压力。
Claude AI 的 CEO 则在一篇长文中泼了冷水,核心观点是:“如果算力成本按历史趋势每年下降 4 倍,那么到 2025 年,模型的性价比应比 2023 年提升 16 倍。但 DeepSeek-V3 的训练成本仅为美国前沿模型的 1/8,这与其性能差距(扩展曲线落后约 2 倍)完全匹配,这不过是正常的技术迭代,而非颠覆性突破。” 他还强调政治观点,算力制约是让 AI 成为美国及其盟友单极优势的关键。
Meta 的首席科学家杨立坤也转发了 DeepSeek 的推文,简短评论:“干得好,开放科学加速进步。” 作为开源领域的坚定支持者,Meta 的 LLaMA 系列一直是开源社区的标杆,DeepSeek r1的发布或许让 llama4会更加充满竞争味道。
DeepSeek-R1 的实际表现
测评数据证明了 DeepSeek-R1 的实力:
● AIME 2024 :79.8%(o1-1217:79.2%)
● Codeforces :96.3%(o1-1217:96.6%)
● Math-500 :97.3%(o1-1217:96.4%)
● SWE-bench Verified (Resolved):49.2%(o1-1217:48.9%)
● LIVE-bench (Global Average):71.38
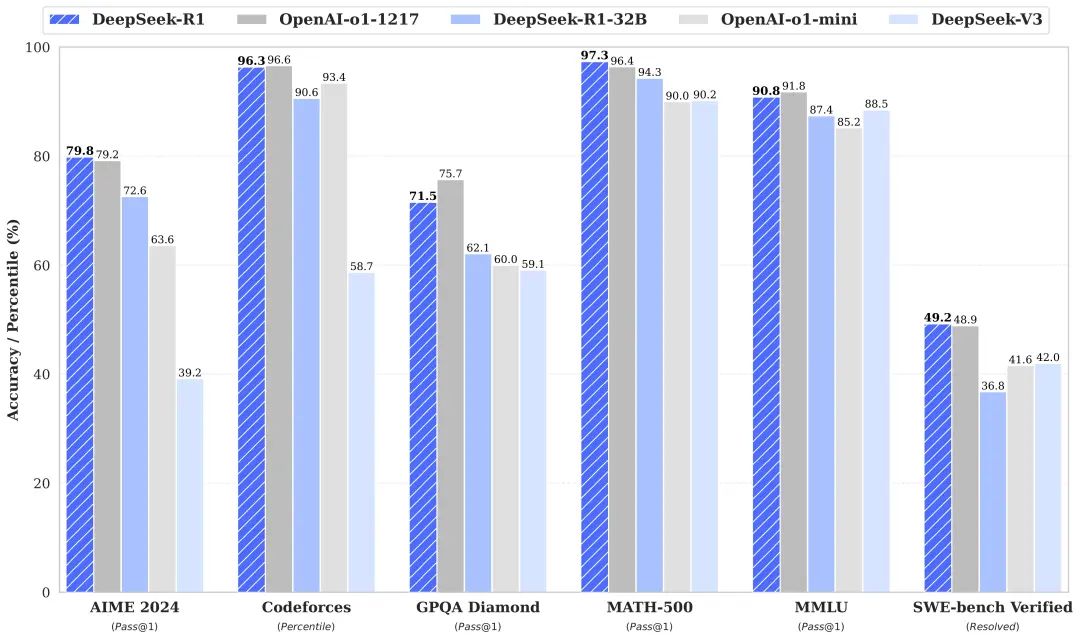
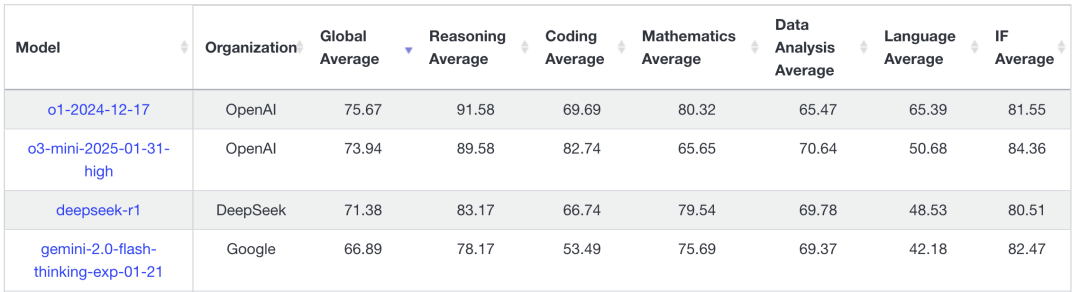
尤其是 SWE-bench、AIME 和 LIVE-bench 这些难度较高的测试,表明 DeepSeek-R1 在数学推理和代码生成上不仅能与 o1-1217 旗鼓相当,在部分场景中甚至略胜一筹。
这几天 r1 的热度吸引了大量实战案例,编程社区的 cursor 和 windsurf 已经纷纷接入使用。为了更好的评估后续值得投资付费对象,笔者也从之前实际工作中用于和 sonnet3.5 以及 o1 探讨的题目拿出来咨询一般,并在一些个人私有题目上进行了测评,给人的感觉是:在绝大多数工作场景是可以和 o1 对标,并部分地理类强逻辑推理题目比 o1/o3-mini 回答更好。 但我认为 sonnet3.5 还有其优势,作为一个非 think推理模型(不会先思考,再回答),处理编码问题、以及连续性探讨,sonnet 3.5 的风格以及感受更良好。另外在更多测试中,我发现 r1 回复不太稳定,期待后面的迭代优化。
deepseek-r1 案例图(分析正确)

deepseek-o1 案例图 (分析错误)

如上是一个自创的私藏题目,其中暗含相对复杂和巧妙的逻辑推理,目前 deepseek r1 能回答出来。观察它的“思维路径”会非常有意思,r1 最开始也会犯 o1的错,凭借直觉认为,“北半球夏至日,三亚影子最短”,但它在得出结论之前,尝试质疑自己,是否还有更短的路径呢?并尝试用公式和角度计算 ,最终推翻了自己之前的结论,并找到更合理的答案。
r1 思维链示意图
所以,对于考虑为哪些模型付费的用户,笔者的个人体验结论是:r1 能平替 o1(o1 pro暂未对比过), 但 sonnet 3.5 仍然值得付费。目前很多网友提供的最佳策略之一是: r1 + sonnet 3.5 组合使用,这和我的实际感受也类似。
而 deepseek 官方 API 由于全球流量爆满,时常出现超时现象。目前已有第三方平台如 poe(免费次数有限,需订阅 20 美元)、chatllm(需订阅 10 美元, 速度较慢)、以及国内 360 提供的 r1专线(免费)。 同时需要注意的是,r1 分为多个版本,其中 671B 参数全量版为最完整,而其他版本可能经过蒸馏后性能有所退化。
DeepSeek-R1 的方法论:规则驱动与纯强化学习
DeepSeek-R1 的成功离不开其核心创新。传统上,我们见过 PPO(近端策略优化)这种强化学习方法,在其中,演员(Actor)生成答案,而评论家(Critic)对答案进行评估,然后指导模型调整策略。这样的双模型结构虽然有效,但需要花费更大成本额外训练评估模型。
而 DeepSeek 的创新在于它将强化学习和规则驱动结合。GRPO(群体相对策略优化)采用的是规则驱动的强化学习。它让模型针对同一问题生成多个候选答案,然后直接利用预设的奖励规则(数学正确性、代码测试、格式合规性等),通过统计比较(均值与标准差)形成相对优势值,指导模型优化策略。就像班级考试,不让老师打绝对分数,而是通过学生之间相互比较找出最佳解法,这种方式既降低了训练成本。
值得一提的是,DeepSeek-zero 首次采用了纯强化学习的突破,而不是从策划的数据集中学习,使其能够在数千次迭代中自我改进。
例如,考虑一个训练用于下棋的 AI 模型。它不是从历史游戏的固定数据集中学习,而是仅通过象棋的基本规则进行编程。然后,它进行自我对弈,不断尝试各种走法。最初,模型执行次优动作,导致失败。然而,通过迭代对弈,它识别出有效策略,并强化有助于胜利的走法,同时摒弃无效的走法。这一试错过程由 RL 原则指导,使 AI 能够开发出超越人类直觉的策略。DeepSeek-zero 正式用类似的策略,给顶基本的奖励规则,模型自己产生了“顿悟”时刻——即模型自己学会主动暂停思路,并重新评估以发现新的解决方案。
中美 AI 竞争
DeepSeek-R1 的发布不仅是技术上的一次突破,也是中美 AI 竞争格局的缩影。回顾 19 世纪的工业革命,第一次工业革命英国以蒸汽机与纺织机械独领风骚;第二次工业革命则是美国与德国共同推动电力与化工的规模化应用,当时的特点是德国为中心的欧洲擅长理论基础,而美国则在商业应用和规模化中非常有优势,比如福特汽车流水线等。
而当下的 AI 革命中,美国在“从 0 到 1”的基础创新上独树一帜(比如 Transformer 架构、GPT 系列),而中国则在“从 1 到 N”的工程化落地上有优势——比如大模型成本优化还是场景适配。 虽然总是有网友吐槽和嘲讽:“当前的 AI 热是不是到了第7,第8 ,第 N 次工业革命了?” ,不管人们谈论到底有多少泡沫,AI 的竞争是已经事实摆在战略层面,中国的政府工作报告去年首提“人工智能+”,而特朗普上任提出的“星际之门” AI 计划。
结
正如杨立坤所言:“开放科学加速进步。” 截止本篇发文当日,openai 开始提供面免费的 o3-mini ,这正是竞争带来的用户选择多样化。然而,竞争仅仅才刚刚开始。春节过后,2025 年 qwen、llama、grok、 mistral 等将如何应对这波开源推理模型大火爆和竞争呢?
⚠️ 本文自动同步自公众号,排版可能异常,其包含图片、视频内容可能无法正常显示和播放。
原文链接:点击查看微信公众号原文
文档信息

