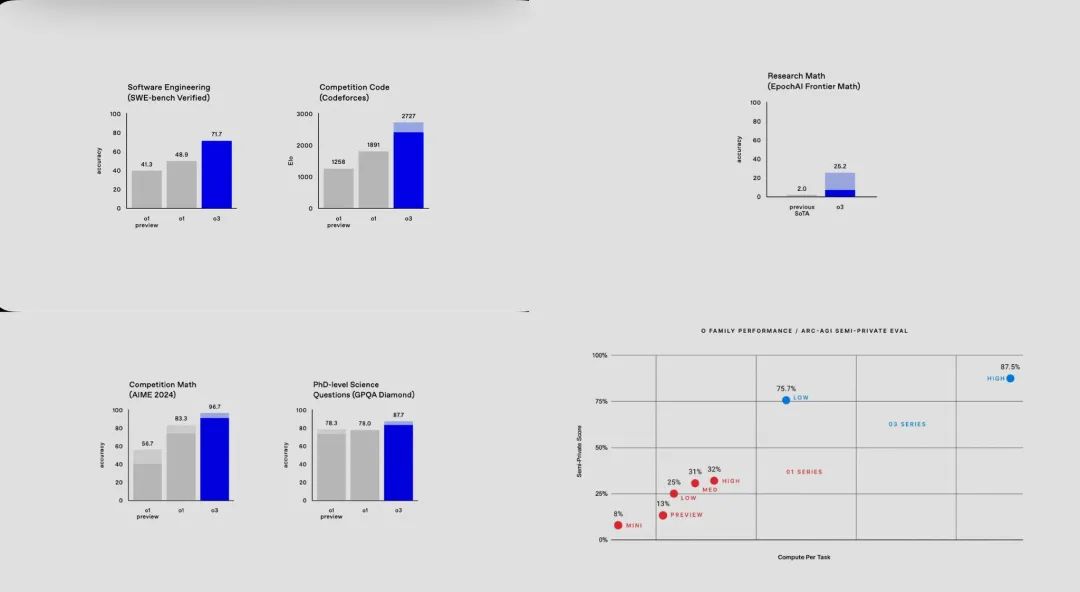
公布 o3的几个核心指标,并分别进行解释其背后带来的意义SWE-Bench Verified: 71.7%PhD level science (GPQA): 87.7%Frontier Math: 25.2% (previous best was 2%)由于笔者对 swe-bench 研究最多,重点提下这个指标。swe-bench是2024年上半年普林斯顿大学发布的一个衡量 AI 解决现实世界软件问题的能力。现实的软件研发是非常全局性的,比如定位一个复杂框架源码中的 bug,通常需要对整个仓库进行了解,并分析出具体问题在哪,然后尝试自己测试、验证,是否修复了 bug,由于仓库的庞大,我们不可能一次性把代码丟给模型快速定位,而必须让模型对 bug 进行推理,逐步阅读关键代码,发现新线索,验证不同方案,才能找到问题。swe-bench刚刚出来的时候,纯粹的 LLM 比如gpt3.5通过率 0.5%, 顶级模型gpt4 和 claude.ai 等都只能个位数 2%左右的通过率。而当时业界普遍的策略是采用复杂的 Agent 多轮思考迭代,最强的系统是 devin,达到12%。此后这个榜单被其他各种更复杂的 Agent策略所突破,最新达到40%多。o1预览版出来,实际我对它很失望,因为宣传最具推理能力的模型,在 swe-bench竟然只有30%左右,还不如 Agent系统。在今年中旬的时候,我认为这个指标能在年底突破50%不太可能。这次 o3 直接重磅宣布 71%的通过率,非常震惊。Codeforces Rating 是 Codeforces 平台用来衡量用户算法竞赛水平的一个分数系统。基于 Elo Rating 的改进算法,每场比赛结束后,系统会根据用户的表现(排名、通过的题数等)调整分数。表现比预期好:Rating 增加。表现比预期差:Rating 减少。这有点像王者荣耀,LOL等巅峰赛机制。Codeforces 每次比赛的题目都是全新设计或基于新颖改编,由出题人和审核团队精心挑选,当然题目类型可能会重复,但是测试用例通常由出题人设计或通过程序生成,难以预测,甚至隐藏了“恶意用例”来验证程序的健壮性。模型能在这类比赛拿到高分,仅仅的记住历史题目是不够的,而必需获对这类问题模式的通用理解,才能泛化到任意具体的新题目,获得高分。用于评估人工智能(AI)模型在生物学、物理学和化学等高级科学领域推理与理解能力的数据集,但题目相对固定,容易泄露,目前看 o3 在这个指标虽提高明显,但个人认为这种题库会走向相对饱和,参考价值没有动态题库大。FrontierMath 的题目由一组顶尖的数学家和专家团队设计和审核。这些数学家包括国际数学奥林匹克(IMO)的金牌得主和菲尔兹奖(Fields Medal)获得者等,比如知名数学家陶哲轩。这个指标个人认为非常有含金量。 到目前为止,GPT-4、Claude 3.5等在FrontierMath基准测试中的表现非常差,成功率不到2%。题目是由专家团队原创的,并且这些问题没有在公开的数学出版物、学术会议或其他平台上发布过。这意味着这些问题对于AI模型而言是“新鲜的”,没有被提前收录进训练数据中,从而避免了AI通过互联网或其他途径获取答案的可能性。oepnai o3 25.2%的突破率提升非常明显。François Chollet -Keras的创建者,Keras是一个开源深度学习库,被超过250万开发人员采用-发表了有影响力的论文“关于智能的衡量”,他在论文中介绍了“通用人工智能的抽象和推理语料库”(ARC-AGI)基准,以衡量人工智能技能获取对未知任务的效率。为了朝着更智能的系统迈进,我们需要定义和评估智力。但衡量特定任务技能并不能很好地代表智力。技能很大程度上受先前的知识和经验的影响。无限的先验或无限的训练数据允许开发人员为系统“购买”技能水平,这掩盖了系统自身的泛化能力。智力存在于广泛的或通用的能力中,它的标志是技能的获得和概括,而不是技能本身。AGI是一个可以在训练数据之外有效获取新技能的系统。它避免依赖任何不属于这些先验知识的信息,例如后天知识或文化知识,例如语言。该评估系统里的“公共训练集” 是用来训练模型的数据集,这部分数据是开放的;而 “半私有评估集” 是一个更受限制的测试集,并不容易公开污染。OpenAI的新o3系统--在ARC-AGI-1得分为87.5%。志着人工智能推理能力的显著进步。计算成本,o3 低计算模式下,每个任务 20美元,高计算模式数千美元。在 GPU 等计算资源未大规模白菜价之前,人脑拥有更大的成本优势。 看上去会继续利好英伟达等 GPU 公司。但历史上第一台计算机ENIAC的成本造价也非常高,它需要大量的硬件组件、真空管、磁性存储设,占据了大约 167平方米 的空间,消耗了大约 150千瓦 的电力,这在当时是巨大的消耗。相比今天的计算机,ENIAC的成本非常高,但它的计算能力却非常有限。ENIAC的运算速度大约是 5,000次加法运算每秒,经过半个世纪的发展,智能手机或个人电脑的处理器每秒钟可以执行数十亿次运算,而价格通常仅为几百美元,还能装进口袋。历史证明 ,任何只要在技术路径上证明了可行性的系统, 不管最初成本多高,最终能通过大规模的工程迭代优化进入低成本时代。
⚠️ 本文自动同步自公众号,排版可能异常,其包含图片、视频内容可能无法正常显示和播放。
原文链接:点击查看微信公众号原文
更新时间: