实测苹果 mac M4 pro 性能提升多少(前端 / 大模型/游戏)
(2024年11月旧文)
最近国补,广东地区针对 mac 也在补贴品类系列。 20% 补贴下来 mac mini M4 3000 多,M4 pro 8900,再叠加各种活动,应该是苹果史上最具性价比时刻。
8 号当天就拿到了 24g 入门版 M4 pro(12+16),体验了很久,并对比公司的 M1(8+8)、对象的M3(8+10),自己17年的intel 古董做了一些测试,有一些个人数据,迟迟没有发出来。这里就给大家看下,主要涉及前端领域以及大模型推理(顺带玩了一把游戏)。
官方数据
在之前,我们先放官方的性能数据

官方的性能对比提高有点惊人,但注意“最高”两个字,很可能是更好利用多核 GPU 比如渲染视频等领域。 然而笔者主要关注占使用频率最高的前端开发构建和离线模型推理。下面主要对比 intel (17) vs M1 vs M3 vs M4 pro ,由于测试是纯手工多次执行并观察,加以实际体验感受为主,仅供参考(可能不少地方有纰漏)。
前端项目
中小型 node 项目构建
被测试的第一个项目属于典型的日常项目,基于 nest + node 构建
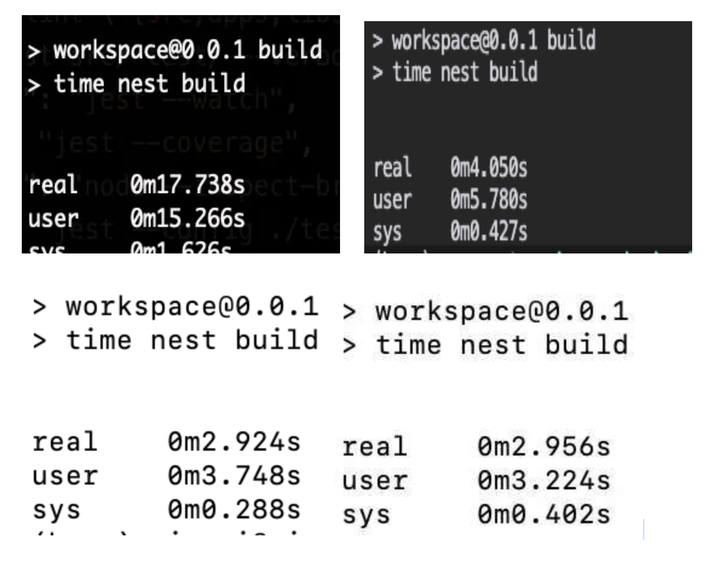
| 17(Intel) macbook pro 15寸 | mac mini M1(8+8) | macbook air m3 (8 +10) | mac mini M4 pro (12 + 16) |
|---|---|---|---|
| 17.7s | 4.0s | 2.92s | 2.65 |
上面明显看到 M 到 17 年英特尔提升明显,而 M3 到 M1 提升很多,但 M4 pro 相对 M3 提高有限。
大型项目构建
vscode 源码超百万,在前端领域属于不多见的复杂项目了,让我们尝试编辑构建,看实际速度。

node 14
| 17(Intel) macbook pro 15寸 | mac mini M1(8+8) | macbook air m3 (8 +10) | mac mini M4 pro (12 + 16) |
|---|---|---|---|
| 126s | 未测试 | 82s | 74s |
在 vscode 这种大型项目构建似乎电脑之间没有明显像中小型项目这样有 4 倍的差距,这很有可能是 vscode 构建过程涉及 IO 操作太多(写入大量文件),占据了时间,而这种操作很难拉开距离,M 的速度优势也就不像之前这么大了。
模拟打分测评
为了更纯粹的测试 CPU 性能,我们让 claude 3.5 sonnet 写了一个前端的 ATS 编译、字符串压缩等常见的测试脚本。这个通过统计每个 cpu 迭代的耗时,采用了几何平均值,分数越大越好。
node版本 14
| 17(Intel) macbook pro 15寸 | mac mini M1(8+8) | macbook air m3 (8 +10) | mac mini M4 pro (12 + 16) |
|---|---|---|---|
| 50000 | 91818 | 165390 | 220962 |
同一 node 版本 M4 pro 会高很多,这个分数更符合 M 芯片之间的能力差距,但 M1 只比 17 年高一倍,还是很意外(可能和这个算法实现有关)。
另外测试过程,无意发现一个问题,简单的提高 node 版本,这个分数就会明显提高,比如 node 18 相对 node 14 能提高一个 cpu 版本更新的分数,说明 node 更高版本采用的 js 编译器性能更好。
大模型推理
推理主要使用 llama.cpp 安装后,启动 llama-server 具备可视化交互, 后天log 会自动统计 token。
llama-server -m qwen2.5-14b-it-Q4_K_M-LOT.gguf \
-c 4096 \
--host 0.0.0.0 \
--port 8080
# 默认会使用 GPU 加载,也可通过 --n-gpu-layers 指定为 0 使用 CPU
....
llm_load_tensors: offloading 48 repeating layers to GPU
llm_load_tensors: offloading output layer to GPU
llm_load_tensors: offloaded 49/49 layers to GPU
llm_load_tensors: Metal_Mapped model buffer size = 8148.39 MiB
llm_load_tensors: CPU_Mapped model buffer size = 417.66 MiB
....
qwen2.5-14b-int4
prompt eval time = 398.68 ms / 20 tokens ( 19.93 ms per token, 50.17 tokens per second)
eval time = 340.81 ms / 8 tokens ( 42.60 ms per token, 23.47 tokens per second)| 17(Intel) macbook pro 15寸 | mac mini M1(8+8) | macbook air m3 (8 +10) | mac mini M4 pro (12 + 16) |
|---|---|---|---|
| 未测试 | 2-4 /s | 9.4token /s | 23 token/s |
| 很早之前测过,印象一字一字出来速度,预计这个速度。 |
qwen2.5-32b-int3
| 17(Intel) macbook pro 15寸 | mac mini M1(8+8) | macbook air m3 (8 +10) | mac mini M4 pro (12 + 16) |
|---|---|---|---|
| 未测试 | 未测试 | 未测试 | 6-7 token/s |
| 16g可能会爆内存。 |
使用 M4 pro 测试大模型有一个出乎意料之外的地方,我们采用 CPU 模式和 GPU 模式速度相差不是很大。在 qwen 32g 下 cpu 速度甚至稳定快 1 token 左右,这里怀疑是 GPU 显存分配不够?,未深究。
上面 qwen 32b-int3 应该是占用 内存 15-16g 。mac gpu 驱动会限制占用总内存的统一内存的部分空间, 第一次启动 mac 24g 内存也会报错。 我们可尝试设置 mac 显存占用突破限制,比如18-19GB
sudo sysctl iogpu.wired_limit_mb=19456但注意,上面这样做有风险,特别是打开了其他占用内存的应用,可能导致内存突然溢出,系统奔溃。
游戏
简单体验了下之前买的《无人深空》,4K,超高画质下,能稳定在 60 -100 帧之间,这个 mac 原生游戏体验没有任何影响。

结论
如果专注前端开发的体验,单核能力 M1 系列比 intel mac 提高是飞跃的,而在 M4 pro 对比 M1 和 M3则是在预期之中的提升,工作不会明显的感受到。(笔者平常工作是使用公司配置的 M1 ,进行中大型前端开发体验都是良好的) 。这是因为前端领域的构建编译基本上主要利用单核能力,无法充分发挥多核优势。如果你工作中打开大量浏览器网页和应用,M4 pro的多核可能会很明显帮助。
对于大模型推理,M1 仅仅能跑起来,无法达到可用阶段。 而 M3 能够达到能用阶段,而 M4 pro 则是体验良好的感受。实际 qwen14b-int4 在 M4 pro 返回的感受和当初的 chatgpt 3.5 很像了,但M4 pro (12+16)明显不适应跑更大的模型(比如32g ),即使显存够了,速度还是跟不上(至少10 token/s 才能正常用吧?)。可以预测,在不久的将来,离线模型会非常成熟,且能能力越来越强。
⚠️ 本文自动同步自公众号,排版可能异常,其包含图片、视频内容可能无法正常显示和播放。
原文链接:点击查看微信公众号原文
文档信息

